Hi, I'm Christoph, the developer of compress-or-die.com.
I hereby ask you to accept the cookies
of the self-hosted Matomo Tracking software which I use to analyze the traffic to this website.
You can revoke your consent at any time on the following page: Privacy policy.
I am writing this article for multiple reasons. On the one hand I want to push my little baby compress-or-die.com (that I will call COD in the rest of the article). It is in my opinion THE tool to create JPGs with the best file-size/quality ratio. On the other hand there are so many incorrect statements about the JPG format out there and therefore so many wrong tool comparisons, that it is simply important to me to clear up misconceptions with an explanation that is reasonable for every level of understanding.
To make this possible I will overly simplify some aspects for the purpose of answering questions adequately if not perfectly correctly. For example I will presume that a color image has an 8 bit resolution, although the JPG format supports other resolutions.
After reading this article you should understand the functionality of the JPG algorithm. Therefrom it should be clear how the file-size reduction tricks explained at the end of the article work.
Furthermore it should be clear to you why compression tools without settings can only achieve a fraction of the possible file-size reduction.
By the way COD was created to increase maneuverability in digital advertising banners which usually have size-limits somewhere below 200 kB.
Of course you can also use COD for large photographies (2,000px x 2,000px and bigger), but at very large sizes it is often not important to save 20 or 30 kB.
In this case you could use nearly every tool to compress your images. It gets really interesting when you try to gain the biggest savings at very low qualities.
Before we start I want to mention something you should take into account if you compare file sizes.
Assume you've got a JPG from tool XY and the file has 2,350,195 bytes.
Depending on the tool you will get different sizes displayed in kB (https://en.wikipedia.org/wiki/Kilobyte).
The well known tool JPGMini uses the deprecated mode of calculation (1024 bytes corresponds to a kB) and displays 2,295 kB.
Since 1998 the correct way to declare that way to calculate would be with "KiB".
COD uses the correct mode of calculation (1000 bytes corresponds to a kB) and displays 2,350 kB for the same file.
Depending on your operating system or your program you will see either one or the other value. There is utter chaos.
Generally the tendency is to use a system that makes the product appear better.
For this reason JPGMini uses the deprecated mode of calculation... and manufacturers of hard disk drives use the new one because their drive's file-size appears to be bigger.
That's problematic at larger sizes of this unit because the difference increases:
Name
Calculation
Difference
Name
Calculation
Byte (B)
0 %
Byte (B)
Kilobyte (kB)
B / 1000
2.4 %
Kibibyte (KiB)
B / 1024
Megabyte (MB)
kB / 1000
4.9 %
Mebibyte (MiB)
KiB / 1024
Gigabyte (GB)
MB / 1000
7.4 %
Gibibyte (GiB)
MiB / 1024
Terabyte (TB)
GB / 1000
10.0 %
Tebibyte (TiB)
GiB / 1024
If you compare file-sizes from different tools you should download the files and compare them at byte level to get a fairer comparison.
But now it's really time to begin. The source image for my explanations will be the image "Lena" which is one of the most used images in the area of image compression:
Most of the time your images will be in the RGB color model.
That means they will be displayed on your monitor by the three colors (or channels) red, green and blue. If a pixel should be displayed white, all three colors are illuminated simultaneously.
With the correct mixing of red, green and blue light many different colors can be displayed.
And because every color can be dimmed in 256 steps it is possible to display 16.7 (256^3) million colors within the RGB color model.
If you take a look at the individual color channels it looks like this in an artistic illustration:
R
G
B
This is the type of illustration you will often see in JPG or color space tutorials.
Actually more meaningful is the display of the intensity values of the pixels as grayscale values:
R
G
B
A white pixel means the color is shining as bright as possible (with the value 255).
If a color does not exist at a specific point the value for this pixel is 0, so we see a black pixel.
As you can see Lena is recognizable very well on all three images. So every color channel contributes to the overall impression of the image.
In this image the red channel is a little bit more distinctive because the Lena image has a tinge of red.
A JPG however is initially converted from the RGB color model to the YCbCr color model.
This color model separates the lightness information from the color information which looks like this in an artistic illustration:
Y
Cb
Cr
You can see that the lightness channel (Y) contributes very much to the overall impression of the image while the other (color) channels (Cb and Cr) show the image content less well.
The main information content that is spread over all three channels in RGB is now bundled in the lightness channel.
This can be seen better in the illustration of the intensity values of the pixels:
Y
Cb
Cr
If the contrast is stronger and the source image is more recognizable, then there is more information included, that is important for the image.
This redistribution of the data is utilized by discarding 3/4 of the data in the color channels.
Our eye is sensible to lightness and therefore contrasts but a lot less to differences in colors.
This is by the way the reason why you can't see any colors in the dark but are able to find the way in the grayscale perceived environment.
So the data to be saved is just this:
Y
Cb
Cr
The reduction of the color data is called Chroma Subsampling or Color Subsampling.
There are multiple possibilities to adjust this reduction. But common for JPGs is either to reduce the color information to a quarter (called 4:2:0) or to keep the color information (called 4:4:4).
These are also the settings that are offered to you in COD.
There are some cases where you should go without Subsampling (use 4:4:4 instead of 4:2:0), e.g. when using a typeface:
Source
Subsampling 4:4:4
Subsampling 4:2:0
In the following case (taken from here) you will even lose image informationen (the red lines disappear):
Source
Subsampling 4:4:4
Subsampling 4:2:0
With Adobe Photoshop it is not possible to adjust the Chroma Subsampling, it is automatically set.
When an image quality between 100-51 is set, then Subsampling 4:4:4 will be used, otherwise 4:2:0 will be used.
For this reason you will see a sudden greater reduction in file-size if you change the quality from 51 to 50.
So it is not possible in Photoshop to combine a stronger compression (below 51) with clean typefaces.
From time to time you also have images completely without color, grayscale images.
Fortunately the JPG specification was designed for respecting this and to save images completely without the color channels.
Unfortunately there are only a few applications that support this, even Photoshop does not.
If you create a grayscale image in Photoshop and save it as JPG, it will always be a color JPG if you use "Save for web".
As you can see in the following table, the potential to save file size is enormous at small image dimensions (think of thumbnails).
In the following table I've created a grayscale JPG and a RGB JPG of a grayscale image in the same quality.
Dimensions
RGB JPG (Byte)
Grayscale JPG (Byte)
Savings (%)
50 x 50
891
751
15.7
75 x 75
1,379
1,247
9.6
100 x 100
2,011
1,839
8.6
125 x 125
2,648
2,498
5.7
150 x 150
3,447
3,237
6.1
175 x 175
4,196
4,019
4.2
200 x 200
5,164
4,912
4.9
225 x 225
6,306
6,022
4.5
250 x 250
7,263
7,031
3.2
275 x 275
8,424
8,100
3.8
300 x 300
9,446
9,165
3.0
325 x 325
10,794
10,383
3.8
350 x 350
11,994
11,638
3.0
375 x 375
13,389
12,904
3.6
400 x 400
14,508
14,093
2.9
425 x 425
16,353
15,881
2.9
450 x 450
17,925
17,297
3.5
475 x 475
19,373
18,819
2.9
500 x 500
21,191
20,444
3.5
Even at large images you will save up to 3% file size.
Please note: 3% data that is absolutely irrelevant for the presentation of the image.
Of course you are able to generate real grayscale JPGs in COD.
Also interesting are images with included color profiles or other color models like the CMYK color model you want to prepare for usage on the web.
In the browser those images look ugly while they look fine in Photoshop or other image viewers.
Only a few of the "great JPG compressors" are able to handle this.
COD converts those images to the standard sRGB color space and discards the color profile to produce a smaller file with a faithful colour reproduction.
CMYK-JPG
Corrected RGB-JPG
Displayed incorrectly if your images does not support CMYK JPG files
Now things will get a little bit odd which has led Xiph.org’s researcher Tim Terriberry to call JPGs "alien technology from the future".
For reasons of clarity and comprehensibility I will skip the things that are difficult to understand like formulas.
Now the image gets splitted in 8x8 sized pixel blocks, where every block will be compressed by itself without any relation to the compression of any other block.
Furthermore it was assumed that there are just minor changes in an 8x8 pixel block so there should be soft contrasts.
That is important because it was realized that all information data in an image can be expressed by putting cosine curves on top of others.
And the smaller the amplitude of a curve the smaller the value you have to save.
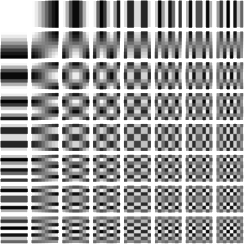
While developing the JPG file format 64 different cosine curves were determined that could express the pixel values of a block.
DCT patterns table
The conversion of pixel intensity values to pattern intensity values is called Discrete cosine transform (DCT).
After that you no longer have 64 wildly mixed pixel intensity values in a block, but values sorted by detail complexity.
The value at the upper left corner contributes most to the appearance of a block. And by layering one pattern after the other from the upper left to the lower right corner the image gets more and more details.
The more patterns from the lower right are discarded, the coarser the image gets. And that is done by JPG at decreasing quality.
Quality 80
Quality 30
Quality 5
At low quality you can perfectly see, that the blocks are just generated from the patterns of the upper left corner from the DCT patterns table.
Zoom of the image at 300% with quality 5
Additionally this image shows very well where the typical block artifacts come from.
But what does it mean if you set the quality slider in your prefered graphics editor to 70 (at a scale from 1-100)? Or to 7 in a different program (at a scale from 1-15)?
Or to "Aggressive"? How does it work that patterns of the lower right corner are getting discarded?
By using the patterns table you now have intensity values for the corresponding patterns that represent the current 8x8 pixel block.
Assume you have a 148.765 as value for the second pattern at the upper left corner.
Because smaller values are simpler to compress we determine a number to divide the value by, e.g. 16, and round the value we got:
148.765 / 16 = 9.29781 = 9
This intensity value is now small and takes up less space by discarding the decimals.
For every pattern of the table we determine a divisor. This new table created with these values is called a quantization table and will be embedded in the JPG file.
And with the help of this table we are able to restore the initial value:
9 * 16 = 144
OK, it isn't exactly correct. But it's close to the initial value of 148.765. Your eye will not see any difference.
In the JPG specification it was determined such a table looks like this:
Quantization table for JPG quality 50
16
11
10
16
24
40
51
61
12
12
14
19
26
58
60
55
14
13
16
24
40
57
69
56
14
17
22
29
51
87
80
62
18
22
37
56
68
109
103
77
24
35
55
64
81
104
113
92
49
64
78
87
103
121
120
101
72
92
95
98
112
100
103
99
You can clearly see that the values get bigger as you get further into the area of the details in the lower right corner.
Because rounding errors at restoring the initial values are getting bigger at bigger quantization values, the details are slightly different to the original image.
But that's OK, because our eye can't see differences in busy areas of the image or can't classify them as correct or wrong.
In the normal case this table should be used at a quality value of 50. And it should be adjusted by a formula for a quality value of 30.
Now you shouldn't forget that this quantization table is just a suggestion and the generated quantization table is embedded in the JPG anyway.
So every manufacturer of graphics software or cameras creates its own "better" quantization tables and uses them.
And also the formula to derive a quantization table from quality factor 50 will be different for every manufacturer.
Maybe they have special tables for specific quality levels or even specific image content.
In a nutshell: The quality level of a JPG is only a handy setting offered by the manufacturer for its quantization tables and has no relation to the JPG specification. So it is not comparable between different programs.
There are more than sextillion possibilities to create a JPG by quantization tables.
So to compare the results from different programs you could create JPGs with the same size and decide which seems to have the better quality.
Or use metrics to estimate the perceived quality like SSIM or PSNR.
But keep in mind that those metrics are far away from simulating the human perception... which is absolutely subjective by the way.
The data of a JPG file can be structured in two different ways.
The first possibility is called "Baseline", which arranges the data of the 8x8 pixel blocks one after the other.
When viewing large image files you will recognize the line-by-line display in the browser.
Baseline: 1 ...
2 ...
3 ...
The second possibility is called "Progressive" which put the values of the coarse patterns at the front and the details at the end.
When viewing large image files you will recognize, that you will first see a coarse image that will get better and better.
Progressive: 1 ...
2 ...
3 ...
This page claims there is an estimated 75% chance to get a smaller image with "Baseline" encoding if the JPG is smaller than 10 kB.
And a 94% chance to get a smaller image with "Progressive" encoding if the JPG is larger than 10 kB.
I have positive experiences with those values so COD uses "Progressive" as default value.
Aside from the fact that the user experience is a lot better.
This setting does NOT change the quality of the generated image as I've read occasionally.
The most famous artifacts of the JPG compression. They appear because every 8x8 px block is compressed for itself. By the usage of the quantization inaccuracies in the rendering occur at the edge of a block. The right edge of a block could be slighlty darker while the left edge of the next block could be slightly brighter. A visible edge appears.
Seen often if detailed and flat areas occur in the same 8x8 px block because the JPG algorithm has to use a pattern of the lower right corner which can't be turned off for the flat part.|
Now since we know the way the JPG is built, we can utilize some peculiarities to reduce the file size apart from the quality settings.
That is probably not interesting for those people among you that just want to save photographs, because the image content might get changed.
But for the others, who are forced to keep file size limits, this could be very interesting.
Of course it's possible to argument with the quality too: If you use those tricks, you could increase the quality to get an image with the same size but with less block boundary artifacts and less mosquito noise.
By the way you have many more possibilities if you have to create images for the browser environment because you can get much more out of your images with the creative usage of CSS and Javascript.
To be able to create a high quality JPG, your source image also has to be of technically good quality and should not have been compressed with a Lossy algorithm like JPG before.
If you create a JPG from high quality material, it will be smaller and will look better than a one created from a heavily compressed JPG.
It is best to create a PNG (lossless image format) from your image composition and to upload this to COD.
In most cases it should also be ok to use the images from your digital camera, because cameras are usually saving JPGs in high quality levels.
You should be sure to have sharp edges at the edges of your 8x8 pixel grid in order to help the JPG algorihm not to take patterns from the DCT patterns table that are intended for the usage of flat areas.
At the following image the typeface and the box where shifted down by 1px to align the elements at the grid. The aligned version is not just a lot smaller, also the box and the typeface are a little bit sharper.
2,425 B
1,316 B
Aligned on the grid.
Maybe you have to adjust the dimensions of the elements or to shift them independently. But it's worth it.
As you have seen above in the context of low-contrast areas (so "smooth" information changes) an image can be saved smaller the lower the contrasts in the individual channels are.
That is the reason a JPG gets smaller if we reduce the contrast because it lowers the differences of the data in the lightness channel.
It is the same with the reduction of the saturation that corresponds to a contrast change in the color channels.
How strong you apply those changes is up to you.
But you should keep in mind that changes in the lightness channel have more impact than changes in the color channels (as far as file-size and quality are concerned).
By using a slight blur the data can be represented better by a cosine curve and thus the JPG is smaller.
But because edges are getting blurred too and the eye is trained to perceive edges I recommend using the Selective blur (available in COD).
This algorithm blurs only flat areas but not edges. It's something like the counterpart of the Unsharp mask that sharpens an image.
Normally JPG does not support transparency. But by using Javascript we are able to compensate this flaw, as long as the image is used in a web environment.
Just upload a transparent PNG to COD and you will get a transparent JPG with the corresponding HTML code you need to embed it into your website.
Especially with large transparent images like pictures of products the file size will be a far below the file size of a transparent PNG.
This great feature of COD allows to save specific areas of your image in a different quality than the others.
Actually this is not supported by the JPG specification but with a little trick it is possible nonetheless.
This is really useful in order to sharpen elements that are in the visual field of the viewer while unimportant elements can be left with a lower quality.
In the following image the background has a lower quality than Lena herself. But because human faces attract the human perception, you don't notice.
14,463 B
12,672 B
With selective quality.
I hope this article gave you a little insight into the functionalities of the JPG algorithm and maybe you've learned how to save a few more bytes on file size.
If you still have questions, suggestions or wishes, drop me a line.
Otherwise feel free to experiment a little bit with the Lena image:
Ben from Compress-Or-Die explains the two quality sliders in the JPEG compressor, their meaning, and how the human eye perceives brightness and color information differently.
He also discusses the quantization table, which determines how much an image is compressed, and how the formula used to calculate the table can differ between programs or online services.
Ever wondered why some of your PNGs are of large file size while similar PNGs are so small?
Since this question comes up so often, I have written a follow-up to my article "Understanding JPEG" to explain the bare necessities of the PNG compression algorithm in layman's terms.
At the end you will also get 7 tips on how to get your PNGs to a REALLY small file size.
There are a lot of articles about online image compression tools in the net, most of them are very superficial.
Usually they end with a simple: "It generates smaller pictures, so it's got to be better."
Learn why such statements are most of the time meaningless, understand the technical background, and find out which tool you should use as of today.
You don't like ads? Support Compress-Or-Die and become a patron who does not see ads. Your upload limit gets doubled too!
News
COD says Goodbye
2026-06-24
After 10 years of compress-or-die.com, it’s time for me to say goodbye. It’s been a great time—I’ve learned a lot technically, but I’ve also met some wonderful people.
compress-or-die.com was created back then to get the most out of graphics for small banners. At the time, I was still working at an advertising agency. And over time, it just kept growing and growing.
But some of you may have noticed that over the past two years, there have been hardly any changes, and there hasn’t been much from me to read—which was quite different back in the day.
But a lot has changed in my personal life: children, new and different hobbies, and health issues have shifted my focus in other directions. And so, I had less and less time and motivation left for this project that was once so close to my heart.
For this reason, this chapter is now coming to an end. I’d like to thank all of you for using COD and for providing such great feedback, which helped COD grow so much.
I’d especially like to thank the Patrons who have covered the server costs over the past few years. Thank you so much!
On July 25, 2026, I will send COD into its well-deserved retirement.
All the best to you all,
Christoph
Check out our Reddit channel if you want to comment on the news.