Hi, I'm Christoph, the developer of compress-or-die.com.
I hereby ask you to accept the cookies
of the self-hosted Matomo Tracking software which I use to analyze the traffic to this website.
You can revoke your consent at any time on the following page: Privacy policy.
Diesen Artikel schreibe ich aus mehreren Gründen. Zum einen, um mein kleines Baby compress-or-die.com (das ich im Artikel jetzt COD nenne) zu pushen, das meiner Meinung nach DAS Tool zum Erstellen von JPGs mit dem bestmöglichen Dateigrößen-Qualität-Verhältnis ist. Zum anderen kursieren im Netz so viele falsche Aussagen über das JPG-Format und davon ausgehend dermaßen viele falsch angestellte Tool-Vergleiche, dass es mir einfach wichtig ist, mit einer für wirklich alle Leute verständlichen Erklärung für Aufklärung zu sorgen.
Damit das aber möglich ist, werde ich einige Teilaspekte vereinfacht darstellen, solange es dem Verständnis dient, auch wenn es vielleicht nicht exakt ist. Zum Beispiel gehe ich bei der Farbdarstellung von einer 8-Bit-Farbtiefe aus, obwohl JPG ja auch noch andere Farbtiefen unterstützt.
Nach diesem Artikel sollte euch grundsätzlich klar sein, wie der JPG-Algorithmus funktioniert. Darauf aufbauend solltet in dann verstehen, wie die Tricks zur Dateigrößenverringerung funktionieren, die am Ende des Artikels erklärt werden.
Außerdem sollte jedem dann klar sein, warum Komprimierungs-Tools ohne Einstellungsmöglichkeiten nur einen Bruchteil von dem ausreizen, was an Dateigrößenverringerung möglich ist.
Erstellt wurde COD übrigens, um mehr kreativen Spielraum in digitalen Werbe-Bannern zu haben, deren Größe meist um irgendeinen Dateigrößen-Wert von unter 200 kB beschränkt ist.
Natürlich könnt ihr mit COD auch große Fotografien (2.000px x 2.000px und größer) verkleinern, aber bei sehr großen Bildern und hohen Qualitätstufen ist es meist gar nicht wichtig, ob man hier 20 oder 30 kB spart. Da könnt ihr fast jedes Tool verwenden. Interessant wird es eigentlich erst, wenn man versucht, aus kleinen Qualitätsstufen möglich viel herauszuholen.
Bevor wir anfangen, möchte ich noch etwas erwähnen, was man beachten sollte, wenn man Dateigrößen vergleicht.
Mal angenommen, ihr erhaltet im Tool XY ein JPG, welches 2.350.195 Bytes groß ist.
Je nach Tool werden euch jetzt verschiedene Größen in kB angezeigt (https://de.wikipedia.org/wiki/Byte).
Das ziemlich bekannte JPGMini z.B. verwendet die veraltete Berechnungsweise (1024 Byte entsprechen einem kB), die seit 1998 eigentlich KiB geschrieben werden müsste, und zeigt euch 2.295 kB an.
COD verwendet die korrekte Berechnungsweise (1000 Byte entsprechen einem kB) und zeigt euch für die gleiche Datei den größeren Wert 2.350 kB an.
Je nach Betriebssystem oder Programm sehr ihr entweder den einen oder der anderen Wert. Dort herrscht ein ziemliches Chaos.
Bei Dateigrößenvergleichen wird meistens das ausgewählt, was einen selbst besser glänzen lässt.
Deshalb verwendet JPGMini die alte Berechnungsweise... und Festplattenhersteller beim Anpreisen der Speichergrößen wenig überraschend die neue Berechnungsweise, da die Festplatten dann auf dem Papier größer wirken.
Das ist bei zunehmender Größer der Einheit aber recht problematisch, da die Differenz dann zunimmt:
Name
Berechnung
Differenz
Name
Berechnung
Byte (B)
0 %
Byte (B)
Kilobyte (kB)
B / 1000
2,4 %
Kibibyte (KiB)
B / 1024
Megabyte (MB)
kB / 1000
4,9 %
Mebibyte (MiB)
KiB / 1024
Gigabyte (GB)
MB / 1000
7,4 %
Gibibyte (GiB)
MiB / 1024
Terabyte (TB)
GB / 1000
10,0 %
Tebibyte (TiB)
GiB / 1024
Vergleicht man also die Dateigrößen aus verschiedenen Tools, sollten die Dateien heruntergeladen und auf Byte-Ebene verglichen werden, weil der Vergleich sonst evtl. falsch ist.
Aber jetzt können wir wirklich anfangen. Ausgangsbild für die folgenden Erklärungen wird das Bild "Lena" sein, welches eines der Standard-Test-Bilder im Bereich der Bildkompression darstellt:
Eure Bilder werden meistens im Farbmodell RGB vorliegen. Das heißt, sie werden über die drei Lichtfarben (oder Kanäle) Rot, Grün und Blau auf eurem Monitor dargestellt. Soll ein Pixel auf dem Bildschirm die Farbe weiß annehmen, leuchten zum Beispiel alle drei Farben gleichzeitig auf. Mit der richtigen Mischung aus blauem, grünem und rotem Licht lassen sich für jeden Pixel die verschiedensten Farben darstellen. Und da jede Lichtfarbe 256 Abstufungen von hell nach dunkel abbilden kann, kommt man auf 16,7 Millionen (256^3) Farben, die das RGB-Farbmodell abbilden kann.
Schaut man sich die einzelnen Farb-Kanäle eines Bildes an, sieht das in einer künstlerischen Darstellung so aus:
R
G
B
Das ist die Darstellung, die man häufig in JPG- oder Farbraum-Tutorials sieht.
Viel aussagekräftiger ist aber eigentlich die Darstellung der Intensitäts-Werte der Pixel als Graustufenwerte:
R
G
B
Ein weißes Pixel bedeutet dabei, dass die Farbe so stark wie möglich leuchtet (also mit dem Wert 255).
Befindet sich an einer Stelle eine der drei Farben nicht, ist der Wert an entsprechender Stelle für diese Farbe also 0, und wir sehen ein schwarzes Pixel.
Wie ihr seht, lässt sich Lena auf allen drei Bildern gut erkennen. Jeder Farbkanal trägt also relativ viel zum Gesamteindruck des Bildes bei.
Bei diesem Bild ist der Rotkanal etwas stärker ausgeprägt (also besser erkennbar), da das Ursprungsbild sehr rotstichig ist.
Ein JPG wird allerdings erstmal vom RGB-Farbmodell in das YCbCr-Farbmodell konvertiert.
Dieses Modell trennt die Helligkeitsinformationen von den Farbinformationen, was in einer künstlerischen Darstellung so aussieht:
Y
Cb
Cr
Bei dieser Darstellung sieht man, dass der Helligkeits-Kanal (Y) sehr viel zum Gesamteindruck des Bildes beiträgt, die anderen Kanäle (Cb und Cr) den Bildinhalt aber nur schwach erkennen lassen.
Der Hauptinformationsgehalt, der in RGB also auf die drei Kanäle verteilt ist, wird hier stark im Helligkeits-Kanal gebündelt.
Noch besser sieht man das wieder in der Darstellung der Intensitätswerte der Pixel:
Y
Cb
Cr
Je stärker der Kontrast und je besser das Ursprungsbild in einem Kanal erkennbar ist, desto mehr für das Bild relevante Informationen stecken in ihm.
Diese Umverteilung der Informationen macht man sich zunutze, indem man 3/4 der Informationen in den Farb-Kanälen einfach weglässt.
Unser Auge kann sehr gut Helligkeiten und damit Kontraste sehen. Farbenunterschiede dagegen um einiges schlechter.
Deshalb kann man auch im Dunkeln keine Farben sehen, während man sich aber trotzden noch in seiner schwarz-weiß-empfundenen Umgebung zurechtfinden kann.
Die Informationen, die im JPG gespeichert werden müssen, sind also nur diese:
Y
Cb
Cr
Dieses Verringern der zu speichernden Farbinformationen nennt man Chroma Subsampling oder Color Subsampling.
Es gibt mehrere Möglichkeiten, dieses Verringern genau einzustellen.
Bei JPGs gebräuchlich sind eigentlich nur das Vierteln der Informationen (bezeichnet als 4:2:0) oder das Beibehalten aller Farbinformationen (bezeichnet als 4:4:4).
Das sind auch die beiden Einstellmöglichkeiten, die in COD angeboten werden.
Es gibt Fälle, bei denen man auf das Subsampling verzichten sollte (also statt 4:2:0 besser 4:4:4 nutzen sollte), z.B. bei Schrift:
Ursprungsbild
Subsampling 4:4:4
Subsampling 4:2:0
In dem nächsten konstruierten Fall (übernommen von hier) verliert man sogar Bildinformationen (die roten Linien verschwinden):
Ursprungsbild
Subsampling 4:4:4
Subsampling 4:2:0
In Adobe Photoshop kann man das Chroma Subsampling übrigens nicht einstellen, es wird automatisch eingestellt.
Bei dem Photoshop-eigenen Qualitätswert von 100-51 wird 4:4:4 verwendet, darunter 4:2:0.
Deshalb gibt es auch einen enormen Dateigrößensprung beim Qualitäts-Wechsel von 51 auf 50.
Es ist dort also nicht möglich, eine stärkere Kompression (unter 51) mit sauberen Schriften zu kombinieren.
Nun hat man ja ab und zu auch mal Bilder komplett ohne Farbe, also Graustufen-Bilder.
Glücklicherweise sieht die JPG-Spezifikation dieses vor, so dass man auch Bilder komplett ohne die Farbkanäle speichern kann.
Unglücklicherweise unterstützen das aber nicht viele Programme, selbst Photoshop nicht.
Erstellt man in Photoshop ein Graustufen-Bild und speichert es dann als JPG ab, ist es immer ein Farb-JPG, wenn man "Fürs Web speichern" verwendet.
Wie ihr in der folgenden Tabelle sehen könnt, ist das Einsparpotential gerade bei kleinen Bildgrößen (wie z.B. bei Thumbnails) enorm.
Hier wurde aus einem Graustufen-Bild jeweils ein Graustufen-JPG und ein RGB-JPG in derselben Qualitätstufe erstellt.
Maße
RGB-JPG (Byte)
Graustufen-JPG (Byte)
Ersparnis (%)
50 x 50
891
751
15,7
75 x 75
1.379
1.247
9,6
100 x 100
2.011
1.839
8,6
125 x 125
2.648
2.498
5,7
150 x 150
3.447
3.237
6,1
175 x 175
4.196
4.019
4,2
200 x 200
5.164
4.912
4,9
225 x 225
6.306
6.022
4,5
250 x 250
7.263
7.031
3,2
275 x 275
8.424
8.100
3,8
300 x 300
9.446
9.165
3,0
325 x 325
10.794
10.383
3,8
350 x 350
11.994
11.638
3,0
375 x 375
13.389
12.904
3,6
400 x 400
14.508
14.093
2,9
425 x 425
16.353
15.881
2,9
450 x 450
17.925
17.297
3,5
475 x 475
19.373
18.819
2,9
500 x 500
21.191
20.444
3,5
Selbst bei größeren Bildern spart ihr so immer noch ca. 3% Dateigröße. Wohlgemerkt 3% an Daten, die für die Darstellung des Bilder völlig irrelevant sind.
In COD könnt ihr selbstverständlich Graustufen-JPGs erzeugen.
Interessant wird es auch, wenn man Dateien mit eingebetteten Farbprofilen oder anderen Farbmodellen (z.B. dem CMYK-Farbmodell) für den Einsatz im Web erstellen möchte.
Im Browser wirken diese Dateien farblich kaputt, während sie in Photoshop richtig aussehen. Nur wenige der "tollen JPG-Komprimierer" können damit umgehen.
COD konvertiert diese in den Standardfarbraum sRGB und verwirft dann das Farbprofil, was zum einen die Datei kleiner macht, zum anderen aber auch für eine saubere Farbdarstellung in den Browsern sorgt.
CMYK-JPG
Korrigiertes RGB-JPG
Wird mit falschen Farben dargestellt, wenn der Browser CMYK-JPGs nicht unterstützt.
Jetzt wird es etwas schräg, weshalb das JPG auch mal "alien technology from the future" von Xiph.org’s Researcher Tim Terriberry genannt wurde.
Ich werde deshalb einige wenige Sachen wie z.B. Formeln weglassen, die nicht der Verständlichkeit dienen.
Das Bild wird in nun 8x8 große Pixelblöcke zerlegt, und jeder 8x8-Block wird einzeln komprimiert, ohne dass es einen Zusammenhang zur Kompression eines anderen Blocks gibt.
Man geht außerdem davon aus, dass sich in einem 8x8 großen Block wenig ändert, also wenige harte Kontraste entstehen.
Dieses ist wichtig, weil man herausgefunden hat, dass sich die Bildinformationen in einem Bild durch das Übereinanderlegen verschiedener Kosinus-Kurven darstellen lassen.
Und je kleiner der Ausschlag einer Kurve ist, desto kleiner ist der Wert, den man für diese speichern muss.
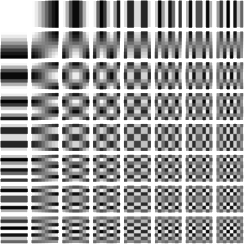
Bei der Entwicklung des JPGs hat man eine Tabelle von 64 verschiedenen Cosinus-Kurven festgelegt, aus denen die Pixel-Werte eines Blockes erzeugt werden können:
DCT-Muster-Tabelle
Die Umrechnung der Pixel-Intensitäts-Werte in Intensitäts-Werte für diese Muster wird Diskrete-Kosinus-Transformation (DCT) genannt.
Man erreicht damit, dass man in einem 8x8-Block nicht 64 durcheinander gewürfelte Intensitäts-Werte hat, sondern nach der Bild-Komplexität sortierte Werte.
Der Wert links oben ist der Wert, der am meisten zum Aussehen eines Blocks beiträgt, und nach und nach wird das Bild durch Übereinanderlegen der Muster von links oben nach rechts unten immer detailreicher.
Je mehr Muster man von rechts unten gesehen also weglässt, desto gröber wird das Bild. Und genau das macht JPG bei nachlassender Qualität.
Qualität 80
Qualität 30
Qualität 5
Bei geringer Qualität kann man sehr gut sehen, wie die einzelnen Blöcke nur aus Mustern der oberen linken Ecke der DCT-Muster-Tabelle generiert werden:
Zoom des Bildes mit Qualität 5 auf 300%
Und dieses Bild erklärt zudem sehr gut, wie es zu der Bildung der typischen Block-Artefakte kommt.
Was bedeutet es jetzt aber, in einem Bildbearbeitungsprogramm den Qualitäts-Regler auf 70 (auf einer Skala von 1-100) zu stellen?
Oder in einem anderen Programm auf 7 (auf einer Skala von 1-15)?
Oder auf "gering"? Wie sorgt es dafür, dass detaillierte Muster aus der unteren rechten Ecke weggelassen werden?
Durch Anwendung der Muster-Tabelle habt ihr jetzt Intensitätswerte für die jeweiligen Muster, die den aktuellen 8x8-Pixel-Block darstellen, z.B. für das zweite Muster von links oben eine 148,765.
Da sich kleine Werte besser komprimieren lassen, überlegt man sich einen Faktor, durch den man den Wert teilt, z.B. 16, und rundet den erhaltenen Wert:
148,765 / 16 = 9,29781 = 9
Dieser Intensitäts-Wert ist jetzt schön klein und verbraucht durch das Weglassen der Nachkommastellen wesentlich weniger Platz bei der Speicherung.
Für jedes Muster der Tabelle legt man nun einen Wert fest, durch den man teilt.
Diese neue Werte-Tabelle, die man Quantisierungs-Tabelle nennt, wird im JPG beim Speichern eingebettet.
Und mit Hilfe dieser Tabelle kann man aus der 9, die als Intensitäts-Wert gespeichert wurde, den ursprünglichen Wert wiederherstellen:
9 * 16 = 144
Ok, stimmt nicht ganz. Ist aber nah dran am eigentlichen Wert 148,765. Das Auge erkennt den Unterschied nicht.
In der JPG-Spezifikation hat man jetzt so eine Tabelle erarbeitet, welche folgendermaßen aussieht:
Quantisierungs-Tabelle für JPG Qualität 50 nach Spezifikation
16
11
10
16
24
40
51
61
12
12
14
19
26
58
60
55
14
13
16
24
40
57
69
56
14
17
22
29
51
87
80
62
18
22
37
56
68
109
103
77
24
35
55
64
81
104
113
92
49
64
78
87
103
121
120
101
72
92
95
98
112
100
103
99
Man sieht deutlich, dass die Werte größer werden, je weiter man in den detaillierten Bereich rechts unten hereinkommt.
Da die Rundungsfehler beim Wiederherstellen der originalen Werte bei größeren Quantisierungswerten auch größer werden, sind die Details also etwas weiter vom Original weg.
Das macht aber nichts, da das Auge Unterschiede in sehr unruhigen Bilddetails eh nicht sehen bzw. als richtig oder falsch einstufen kann.
Im Normalfall sollte es jetzt so sein, dass bei einer Qualität von 50 diese Quantisierungs-Tabelle genommen wird und bei Qualität 30 diese Tabelle durch eine Formel angepasst wird.
Jetzt darf man aber nicht vergessen, dass diese Quantisierungstabelle nur ein Vorschlag ist und Quantisierungs-Tabellen eh in die JPG-Datei eingebettet werden.
Deshalb hat jeder Bildbearbeitungsprogramm-Hersteller und jeder Kamera-Hersteller eigene Quantisierungstabellen, die er für besser hält und deshalb verwendet.
Und auch die Formel zum Berechnen der abgewandelten Tabellen für eine andere Qualität als 50 wird bei jedem Hersteller anders sein.
Wenn sie nicht sogar speziell angepasste Tabellen für bestimmte Qualitätsstufen und sogar bestimmte Arten von Bildern haben.
Kurz: Die Qualitätsstufe eines JPGs ist nur eine handliche Einstellmöglichkeit des Herstellers für dessen Quantisierungstabellen und hat nichts mit der JPG-Spezifikation zu tun und ist somit in keinsterweise zwischen verschiedenen Programmen vergleichbar.
Es gibt weit mehr als nur Trilliarden Möglichkeiten an möglichen JPGs, die über die Quantisierungstabellen erstellt werden können.
Was man zum Vergleich der Resultate aus verschiedenen Programmen also nur machen kann, ist die JPGs bei gleicher Dateigröße zu exportieren und dann zu entscheiden, welches man qualitativ besser findet.
Oder man verwendet Metriken zur Schätzung der wahrgenommenen Qualität wie SSIM oder PSNR, welche aber noch weit davon entfernt sind, das menschliche Empfinden zu simulieren.
Welches davon abgesehen ja auch komplett subjektiv ist.
Dieser Schritt sorgt dafür, dass die übrig bleibenden Werte nach der Quantisierung möglichst platzsparend kodiert werden.
Hier passiert nichts mehr, was für das Verständnis des JPGs maßgeblich wäre.
Die Bilddaten einer JPG-Datei können bei der Speicherung auf zwei verschiedene Arten strukturiert werden.
Die erste Möglichkeit ist "Baseline", durch die die Daten der einzelnen 8x8-Pixel-Blöcke hintereinander abgelegt werden.
Bei großen Bild-Dateien erkennt ihr ein Baseline-strukturiertes JPG daran, dass es sich zeilenweise im Browser aufbaut.
Baseline: 1 ...
2 ...
3 ...
Die zweite Möglichkeit ist "Progressive", durch die erst alle groben Muster gespeichert werden und danach die immer feineren.
Bei großen Bild-Dateien erkennt ihr ein Progressive-strukturiertes JPG daran, dass ihr sofort ein grobes Bild seht, was nach und nach feiner wird.
Progressive: 1 ...
2 ...
3 ...
Diese Seite behauptet, dass bei einem Baseline-Aufbau eine 75-prozentige Chance auf ein kleines Bild besteht, wenn das JPG kleiner als ca. 10 kB ist.
Und eine 94-prozentige Chance auf ein kleines Bild, wenn euer JPG größer als ca. 10 kB ist.
Da ich damit tatsächlich sehr gute Erfahrungen gemacht habe, ist bei COD "Progressive" als Standard eingestellt.
Davon abgesehen, ist der progressive Aufbau auch aus Usability-Gründen zu bevorzugen.
Diese Einstellung ändert NICHT die Qualität des letztendlichen Bildes, wie ich ab und zu gelesen habe.
Die wohl bekanntesten Artefakte der JPG-Kompression. Sie entstehen, weil jeder 8x8-Pixel-Block für sich selbst komprimiert wird. Durch die Quantisierung entstehen Ungenauigkeiten in der Darstellung am Rande eines Blocks. Wird jetzt ein Block am rechten Rand durch die Quantisierung ein wenig dunkler und der darauffolgende Block am linken Rand etwas heller, erscheint eine sichtbare Kante.
Sehr oft zu sehen, wenn kontrastreiche Details und kontrastarme Flächen gleichzeitig in einem 8x8-Pixel-Block auftreten, weil der Algorithmus für die Details ein Detail-Muster aus der rechten unteren Ecke der Muster nehmen muss, welches aber nicht einfach bei der Fläche ausgeschaltet werden kann.
Da wir jetzt ja wissen, wie ein JPG aufgebaut ist, können wir einige Eigenheiten ausnutzen, um die Dateigröße abseits der Qualitätseinstellungen weiter zu verringern.
Dieses ist natürlich nicht interessant für diejenigen unter euch, die einfach nur Fotografien abspeichern wollen, weil durch diese Maßnahmen evtl. der Bildinhalt geändert wird.
Für die anderen, die bestimmte Dateigrößen-Grenzen einhalten wollen oder müssen, kann das allerdings sehr interessant sein.
Man kann natürlich auch über die Qualität argumentieren: Verwendet ihr folgende Tricks, könnt ihr die Qualität höher einstellen und bekommt bei gleicher Dateigröße weniger Block-Artefakte und Mosquito Noise.
Übrigens hat man mehr Möglichkeiten, wenn man Bilder für das Browser-Umfeld erzeugt, weil man dort mit kreativer Verwendung von CSS und Javascript noch mehr aus den Bildern herausholen kann.
Um ein gutes JPG erstellen zu können, muss euer Ausgangsmaterial technisch von guter Qualität sein, sollte also nicht vorher schon einmal mit einem Lossy-Algorithmus wie JPG stark komprimiert worden sein.
Erstellt ihr ein JPG aus gutem Ausgangsmaterial, wird es kleiner sein UND optisch besser aussehen, als wenn ihr das JPG aus einem schon vorher stark komprimierten JPG erstellt.
Erstellt in eurem Grafikprogramm am besten ein PNG (verlustfreies Datenformat) aus eurer Bildkomposition und ladet dieses in COD hoch.
Direkt die Bilder aus eurer Digitalkamera zu nehmen, ist in den meisten Fällen auch ok, weil die Kameras JPGs in recht hohen Qualitätsstufen speichern.
Ihr solltet darauf achten, dass scharfe Kanten an den Rändern des 8x8-Pixel-Rasters liegt, damit der JPG-Algorithmus keine detailreichen Muster aus der Mustertabelle nehmen muss, wo eigentlich nur Fläche vorhanden ist.
Bei folgendem Bild wurde Schrift und Box einfach nur 1px weiter nach unten geschoben, um die Elemente am Raster auszurichten.
Die ausgerichtete Version ist nicht nur bedeutend kleiner, auch die Box und die Schrift sind ein wenig schärfer.
2.425 B
1.316 B
Am Raster ausgerichtet.
Evtl. müsst ihr auch Elemente geringfügig in der Größe ändern oder sie unabhängig voneinander verschieben. Aber es lohnt sich.
Wie wir oben im Zusammenhang mit den kontrastarmen Flächen (also "weichen" Informationsänderungen) gesehen haben, lässt sich ein Bild umso kleiner speichern je kleiner die Kontraste in den einzelnen Kanälen sind.
Daher verkleinert es ein JPG, wenn man vorher den Kontrast verringert, da im Helligkeits-Kanal die Abstände der Informationen verringert werden.
Genauso verhält es sich mit der Verringerung der Sättigung, was eigentlich eine Kontraständerung in den Farb-Kanälen ist.
Wie stark man diese Änderungen anwendet, ist jedem selbst überlassen.
Aber ihr solltet beachten, dass Änderungen im Helligkeitskanal immer mehr Auswirkungen haben als Änderungen in den Farb-Kanälen (was Dateigröße angeht, aber auch Qualität).
Anstatt die Farbe im JPG-Bild zu speichern, ist es vielleicht eine Überlegung wert, euer JPG als Graustufen-Bild abzuspeichern und das Bild nachträglich per CSS einzufärben:
img { filter: sepia(100%); }
16.691 B
13.763 B
Per CSS eingefärbt
Sieht vielleicht nicht exakt gleich, aber man spart etwas Dateigröße, weil man ja keine Farbinformationen im JPG speichern muss.
Durch ein geringfügiges Weichzeichnen lassen sich die Daten besser durch eine Kosinus-Kurve darstellen und das JPG wird dadurch kleiner.
Da aber auch Kanten weichgezeichnet werden und das Auge besonders auf die Wahrnehmung von Kanten geschult ist, empfehle ich, den sogenannten selektiven Weichzeichner (verfügbar in COD) zu nehmen.
Dieser zeichnet nur die Flächen weich, lässt Kanten aber unangetastet und ist so etwas wie das Gegenstück zur Unschärfe-Maske zum Schärfen eines Bildes.
Normalerweise unterstützt JPG keine Transparenz. Aber durch den Einsatz von Javascript kann dieser Makel ausgeglichen werden, solange das Bild im Webumfeld eingesetzt wird.
Ladet in COD mal ein transparentes PNG hoch und ihr bekommt ein transparentes JPG sowie den zugehörigen HTML-Code angeboten, um das Bild in eure Website einbinden zu können.
Gerade bei großen transparenten Bildern wie z.B. Abbildungen von Produkten liegt man damit weit unter der Dateigröße eines transparenten PNGs.
Dieses tolle Feature von COD erlaubt es euch, bestimmte Bereiche des JPGs in einer anderen Qualitätsstufe zu speichern als andere.
Eigentlich ist dieses durch die JPG-Spezifikation gar nicht möglich, aber durch einen kleinen Trick geht es dann doch.
Dieses ist sehr nützlich, um z.B. Bildelemente, die besonders im Blickpunkt des Betrachters sind, schärfer aussehen zu lassen, während die unwichtigen Elemente ruhig etwas weniger Qualität vertragen können.
Bei dem folgenden Bild hat z.B. der Hintergrund eine niedrigere Qualität als Lena selbst. Da aber gerade Gesichter die menschliche Wahrnehmung anziehen, fällt das erstmal nicht weiter auf.
14.463 B
12.672 B
Mit selektiver Qualität.
Ich hoffe, dieser Artikel hat euch einen etwas besseren Einblick in die Funktionsweise eines JPGs gegeben und ihr wisst jetzt auch, wo ihr noch Dateigröße herauskitzeln könnt.
Falls ihr aber noch Fragen, Anregungen, Wünsche o.ä. haben solltet, immer her damit.
Ansonsten könnt ihr jetzt auch gleich mit dem Lena-Bild weiter experimentieren:
Ben from Compress-Or-Die explains the two quality sliders in the JPEG compressor, their meaning, and how the human eye perceives brightness and color information differently.
He also discusses the quantization table, which determines how much an image is compressed, and how the formula used to calculate the table can differ between programs or online services.
Ever wondered why some of your PNGs are of large file size while similar PNGs are so small?
Since this question comes up so often, I have written a follow-up to my article "Understanding JPEG" to explain the bare necessities of the PNG compression algorithm in layman's terms.
At the end you will also get 7 tips on how to get your PNGs to a REALLY small file size.
There are a lot of articles about online image compression tools in the net, most of them are very superficial.
Usually they end with a simple: "It generates smaller pictures, so it's got to be better."
Learn why such statements are most of the time meaningless, understand the technical background, and find out which tool you should use as of today.
You don't like ads? Support Compress-Or-Die and become a patron who does not see ads. Your upload limit gets doubled too!
News
COD says Goodbye
2026-06-24
After 10 years of compress-or-die.com, it’s time for me to say goodbye. It’s been a great time—I’ve learned a lot technically, but I’ve also met some wonderful people.
compress-or-die.com was created back then to get the most out of graphics for small banners. At the time, I was still working at an advertising agency. And over time, it just kept growing and growing.
But some of you may have noticed that over the past two years, there have been hardly any changes, and there hasn’t been much from me to read—which was quite different back in the day.
But a lot has changed in my personal life: children, new and different hobbies, and health issues have shifted my focus in other directions. And so, I had less and less time and motivation left for this project that was once so close to my heart.
For this reason, this chapter is now coming to an end. I’d like to thank all of you for using COD and for providing such great feedback, which helped COD grow so much.
I’d especially like to thank the Patrons who have covered the server costs over the past few years. Thank you so much!
On July 25, 2026, I will send COD into its well-deserved retirement.
All the best to you all,
Christoph
Check out our Reddit channel if you want to comment on the news.